What is a good dataset
 Olivia House
Olivia House A “good dataset” is a dataset that : Does not contains missing values. Does not contains aberrant data. Is easy to manipulate (logical structure).
How do I know if my dataset is good?
- Your Question is Sharp. …
- Your Data Measures What You Care About. …
- Your Data is Accurate. …
- Your Data is Connected. …
- You Have a Lot of Data.
What are some examples of datasets?
What Is a Data Set? A data set is a collection of numbers or values that relate to a particular subject. For example, the test scores of each student in a particular class is a data set. The number of fish eaten by each dolphin at an aquarium is a data set.
What is considered a large dataset?
What are Large Datasets? For the purposes of this guide, these are sets of data that may be from large surveys or studies and contain raw data, microdata (information on individual respondents), or all variables for export and manipulation.What makes a good training dataset?
What factors are to be Considered when Building a Machine Learning Training Dataset? You need to assess and have an answer ready for these basic questions around the quantity of data: The number of records to take from the databases. The size of the sample needed to yield expected performance outcomes.
How big should my dataset be?
The Size of a Data Set As a rough rule of thumb, your model should train on at least an order of magnitude more examples than trainable parameters. Simple models on large data sets generally beat fancy models on small data sets.
How do I choose the best dataset for machine learning?
- Articulate the problem early.
- Establish data collection mechanisms. …
- Check your data quality.
- Format data to make it consistent.
- Reduce data.
- Complete data cleaning.
- Create new features out of existing ones.
What are the five biggest data sets in the world?
- NFA 2018 National Footprint Accounts.
- Social Media Bot Detection by Paragon Science. …
- INC 5000 2018. …
- Citylab Congressional Density Index. …
- Chicago Crime Dataset. …
- Sports Viz Sundays 2018. …
- FIFA World Cup 2018. …
- Video Games Global Sales in Volume 1983-2017. …
What is considered small dataset?
Small Data can be defined as small datasets that are capable of impacting decisions in the present. Anything that is currently ongoing and whose data can be accumulated in an Excel file.
What is data set type?Data Set types A Data Set’s type corresponds to the specific type of data you want to import. For example, there are Data Set types for User Data, Cost Data, Content Data, etc. Depending on the Data Set type, you’ll have different options for the dimensions and metrics (the schema) you can use.
Article first time published onWhat are datasets used for?
Data sets can hold information such as medical records or insurance records, to be used by a program running on the system. Data sets are also used to store information needed by applications or the operating system itself, such as source programs, macro libraries, or system variables or parameters.
What are the key details of datasets?
A data set consists of roughly two components. The two components are rows and columns. Additionally, a key feature of a data set is that it is organized so that each row contains one observation.
Which can be considered as training data?
When considering the machine learning, the ground truth is considered to be the accuracy of the training set’s classification for supervised learning technique. …
What are types of machine learning?
These are three types of machine learning: supervised learning, unsupervised learning, and reinforcement learning.
What is the difference between training data and test data?
What Is the Difference Between Training Data and Testing Data? Training data is the initial dataset you use to teach a machine learning application to recognize patterns or perform to your criteria, while testing or validation data is used to evaluate your model’s accuracy.
What is good accuracy in machine learning?
If you are working on a classification problem, the best score is 100% accuracy. If you are working on a regression problem, the best score is 0.0 error. These scores are an impossible to achieve upper/lower bound.
What is the best algorithm for prediction?
1 — Linear Regression Linear regression is perhaps one of the most well-known and well-understood algorithms in statistics and machine learning. Predictive modeling is primarily concerned with minimizing the error of a model or making the most accurate predictions possible, at the expense of explainability.
Which classifier is best in machine learning?
- Logistic Regression.
- Naive Bayes.
- K-Nearest Neighbors.
- Decision Tree.
- Support Vector Machines.
Why is a small dataset bad?
Small Samples Yield Unreliable Results The smaller your sample size, the more likely outliers — unusual pieces of data — are to skew your findings. Sample size is a count of individual samples or observations in any statistical setting.
What is K in K fold cross validation?
The key configuration parameter for k-fold cross-validation is k that defines the number folds in which to split a given dataset. Common values are k=3, k=5, and k=10, and by far the most popular value used in applied machine learning to evaluate models is k=10.
Is more training data always better?
They both show that adding more data always makes models better, while adding parameter complexity beyond the optimum, reduces model quality. Increasing the training data always adds information and should improve the fit.
Why is a large data set better?
Larger sample sizes provide more accurate mean values, identify outliers that could skew the data in a smaller sample and provide a smaller margin of error.
What is a medium sized dataset?
We define three data set sizes, based on how much of the directory data set fits into available physical memory: Small. The data set fits entirely into physical memory with fully-loaded database and entry caches. Medium. The data set fits in physical memory, and extra physical memory can be dedicated to entry cache.
What is big and small data?
In nutshell, data that is simple enough to be used for human understanding in such a volume and structure that makes it accessible, concise, and workable is known as small data. Big Data: It can be represented as large chunks of structured and unstructured data. The amount of data stored is immense.
What are the 3 V's of big data?
The Three V’s of Big Data: Volume, Velocity, and Variety.
What is a real-world dataset?
A Real-World Dataset is a data set of real-world data records (that represent some sensed event). Context: It can range from being a Small Real-World Dataset to being a Large Real-World Dataset. It can be approximated by a Realistic Dataset. …
What are the 5 sources of data?
- Interview method: …
- Survey method: …
- Observation method: …
- Experimental method:
What is high quality data?
Data that is deemed fit for its intended purpose is considered high quality data. Examples of data quality issues include duplicated data, incomplete data, inconsistent data, incorrect data, poorly defined data, poorly organized data, and poor data security.
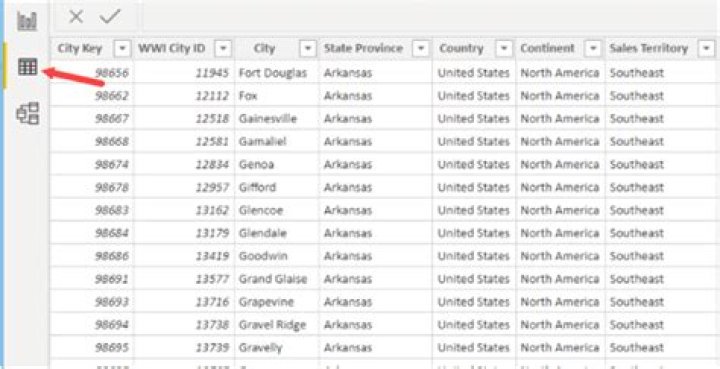
What does a dataset look like?
A dataset (example set) is a collection of data with a defined structure. Table 2.1 shows a dataset. It has a well-defined structure with 10 rows and 3 columns along with the column headers. This structure is also sometimes referred to as a “data frame”.
What are 4 types of data?
- These are usually extracted from audio, images, or text medium. …
- The key thing is that there can be an infinite number of values a feature can take. …
- The numerical values which fall under are integers or whole numbers are placed under this category.
What is dataset in AI?
Oxford Dictionary defines a dataset as “a collection of data that is treated as a single unit by a computer”. This means that a dataset contains a lot of separate pieces of data but can be used to train an algorithm with the goal of finding predictable patterns inside the whole dataset.